

In this post, we’ll look at carbon-aware scheduling using Kubernetes. This post focuses on spatial shifting using Karmada. It follows on from my last post where I looked at temporal shifting using KEDA and the carbon-aware-keda-operator from Microsoft.
Temporal shifting involves running non-time-sensitive workloads at times when the carbon intensity of the electricity grid being used is lower.
Spatial shifting involves moving workloads to physical locations where the grid carbon intensity is lower. This allows workloads that are more time sensitive to be made carbon aware. It also enables a “follow the sun” model to be used to move workloads across different geographies depending on how much renewable energy is available.
However, as with temporal shifting, there may be constraints that prevent spatial shifting. Such as regulatory requirements that data must be stored and processed in certain countries. Data gravity can be another constraint. For example, when training a machine learning model if it needs to fetch large quantities of data from another region this may slow the job, increase costs, and there will be carbon emissions from the network transfer.
This is an area the community has been looking at for some time. Including the paper “A Low Carbon Kubernetes Scheduler” from 2019. I proposed a possible solution using KubeFed in a blog post I wrote for the Green Web Foundation in 2022.
KubeFed has now been retired and replaced by two projects, Karmada and Open Cluster Management.
Karmada
Karmada runs in a control plane cluster and consists of a series of controllers and a Karmada API Server as well as the Kubernetes API Server. Multiple member clusters can then be registered with Karmada.
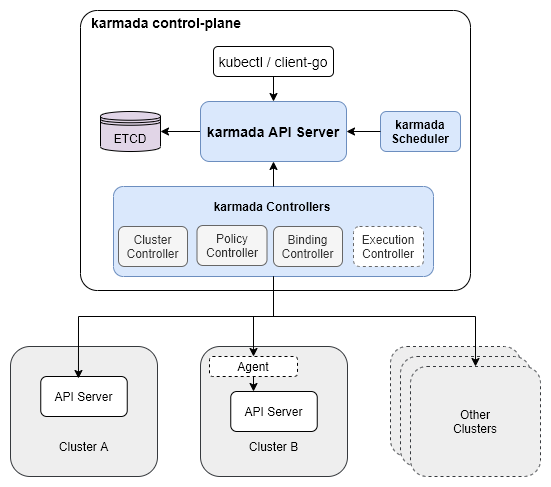
To schedule resources in the member clusters the resource templates are created in the Karmada API server. These can be built-in objects like configmaps or custom resources and CRDs (Custom Resource Definitions). No pods will be scheduled for these template resources in the control plane cluster.
The user then defines a Propagation Policy with which resources to select and where to place them. The member clusters are selected by setting the cluster affinities with the names of clusters. Here is an example policy for an nginx deployment.
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinity:
clusterNames:
- member1
- member2
replicaScheduling:
replicaSchedulingType: Divided
The easiest way to try Karmada is to follow their quick start which creates a control plane cluster and 3 member clusters using kind (Kubernetes in Docker). Just ensure your container engine has sufficient resources for 4 kind clusters!
carbon-aware-karmada-operator
After trying out Karmada I think it has a lot of potential to be used for spatial shifting of workloads. So I’ve created a proof of concept carbon-aware-karmada-operator. The design follows the standard operator pattern of extending the Kubernetes API with a CRD and running a controller in the cluster that watches for these custom resources.
The CRD is called CarbonAwareKarmadaPolicy and here is an example resource.
apiVersion: carbonaware.rossf7.github.io/v1alpha1
kind: CarbonAwareKarmadaPolicy
metadata:
name: nginx-policy
spec:
clusterLocations:
- name: member1
location: DE
- name: member2
location: ES
- name: member2
location: FR
desiredClusters: 2
karmadaTarget: propagationpolicies.policy.karmada.io
karmadaTargetRef:
name: nginx-propagation
namespace: default
For each member cluster, we include its name and the location code used by the carbon intensity API. In this case, it’s
the country codes where the clusters are located but it could also be the name of the electricity grid e.g. CAISO_NORTH
for Northern California. See the next section for more details on the carbon intensity integration.
We also specify how many member clusters are desired and the propagation policy to update to set the cluster affinities.
Right now the scheduling logic is very basic. The operator ranks each member cluster by carbon intensity and selects the desired number of clusters with the lowest values. Every 5 minutes the operator will check if there is new carbon intensity data and repeat the ranking.
grid-intensity-go
To access the carbon intensity data the operator uses the grid-intensity-go library from the Green Web Foundation (which I’m a contributor to). As well as being a Go library it also has a CLI and a Prometheus exporter for accessing carbon intensity data.
It supports multiple data providers including Electricity Maps and WattTime who provide data for multiple geographies. Both providers have commercial plans and free plans for non-commercial use. For WattTime their free tier provides a relative value that can be used for ranking clusters but is less accurate than using absolute values.
Another important difference is Electricity Maps provides average carbon intensity and WattTime provides marginal carbon intensity. See this blog post for more details.
grid-intensity-go provides valid_from and valid_to dates for each location and the operator has an in-memory cache so it only requests
new data when needed. This avoids hitting API rate limits and reduces the energy usage of the operator by reducing the number of API calls it makes.
Status resource
The operator sets the status of the custom resource to show which clusters were selected and the current carbon intensity data.
apiVersion: carbonaware.rossf7.github.io/v1alpha1
kind: CarbonAwareKarmadaPolicy
metadata:
name: carbon-aware-nginx-policy
spec:
...
status:
activeClusters:
- member1
- member2
clusters:
- carbonIntensity:
units: gCO2e per kWh
validFrom: "2023-07-12T11:00:00Z"
validTo: "2023-07-12T12:00:00Z"
value: "55.00"
location: FR
name: member1
- carbonIntensity:
units: gCO2e per kWh
validFrom: "2023-07-12T11:00:00Z"
validTo: "2023-07-12T12:00:00Z"
value: "144.00"
location: ES
name: member2
- carbonIntensity:
units: gCO2e per kWh
validFrom: "2023-07-12T11:00:00Z"
validTo: "2023-07-12T12:00:00Z"
value: "194.00"
location: DE
name: member3
provider: ElectricityMap
The operator also emits Prometheus metrics per cluster with the carbon intensity and whether they are active.
curl -s http://localhost:8080/metrics | grep carbon_intensity
# HELP carbon_aware_karmada_operator_cluster_carbon_intensity Cluster carbon intensity
# TYPE carbon_aware_karmada_operator_cluster_carbon_intensity gauge
..._cluster_carbon_intensity{active="false",cluster="member3",location="DE"} 196
..._cluster_carbon_intensity{active="true",cluster="member1",location="FR"} 51
..._cluster_carbon_intensity{active="true",cluster="member2",location="ES"} 151
Conclusion
This first version of the operator is a prototype to validate the idea and the approach. The current scheduling logic is basic and could be improved. It’s also likely that more CRDs need to be managed. Karmada has support for Federated HPA (Horizontal Pod Autoscaler) which would be very useful but uses additional CRDs.
If you want to try out the operator check out the quick start. Feedback is much appreciated and if you’re interested in collaborating to develop the operator further please do get in touch.
Since the carbon intensity of electricity grids depends on how much renewable energy is available by moving these workloads we can reduce the carbon emissions of our software. The scheduling described here is dynamic and the workloads deployed need to be fault tolerant so they can be moved without impacting users.
However, less dynamic scheduling is also possible and can be very effective. A great example is included in the Green Software Foundation docs to move workloads between hemispheres as the seasons change to maximise the amount of daylight hours.
My blog doesn’t have comments but you can discuss the ideas here in this GSF discussion on carbon aware scheduling with Kubernetes.
Credits
- Photo by Matthew Henry on Unsplash.
- Karmada architecture diagram
{kind=link}